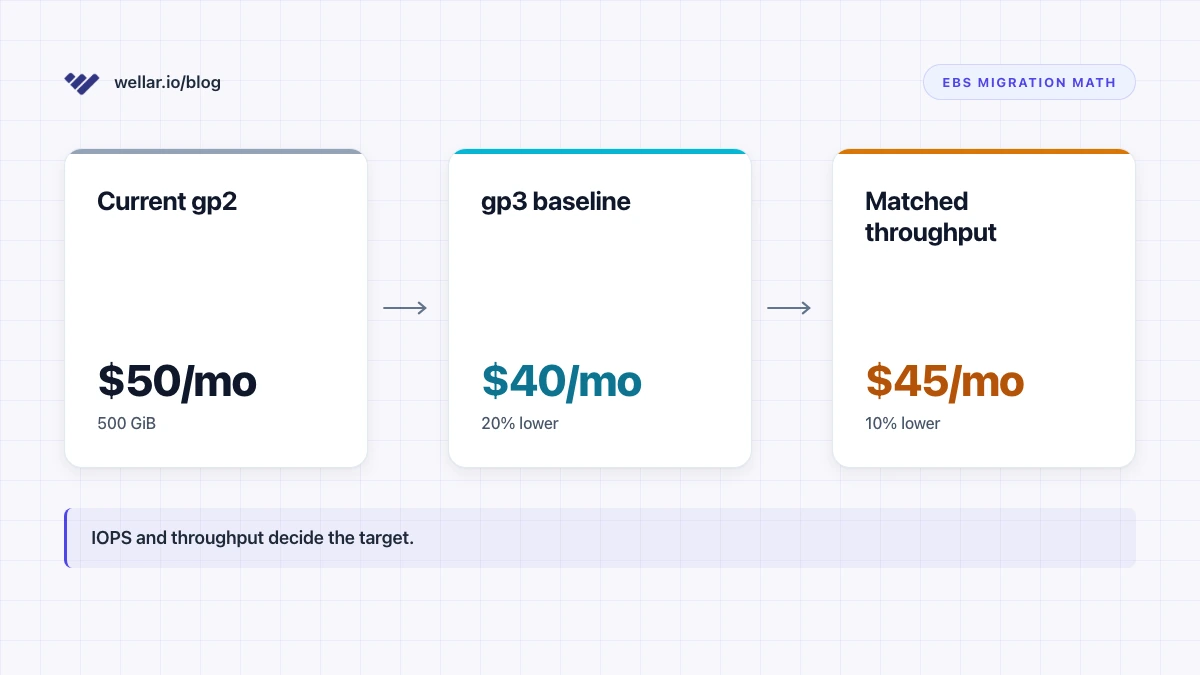
A 500 GiB gp2 EBS volume is a $50/month line item in the US East examples AWS publishes. The advice everyone repeats is simple: migrate it to gp3, pay $40/month, take the 20% win, go home.
Then you open EC2 Console -> Volumes -> Modify volume, change the type to gp3, and leave the performance fields alone. AWS preserves the source volume's throughput. The new price is not $40/month. It is $45/month.
That is not a disaster. A 10% storage cut is still a cut. But it is the footnote that turns an AWS EBS gp2 vs gp3 migration from a checkbox into an engineering decision. The volume type is not the hard part. The hard part is deciding whether you actually need to keep the performance that gp2 gave you by accident.
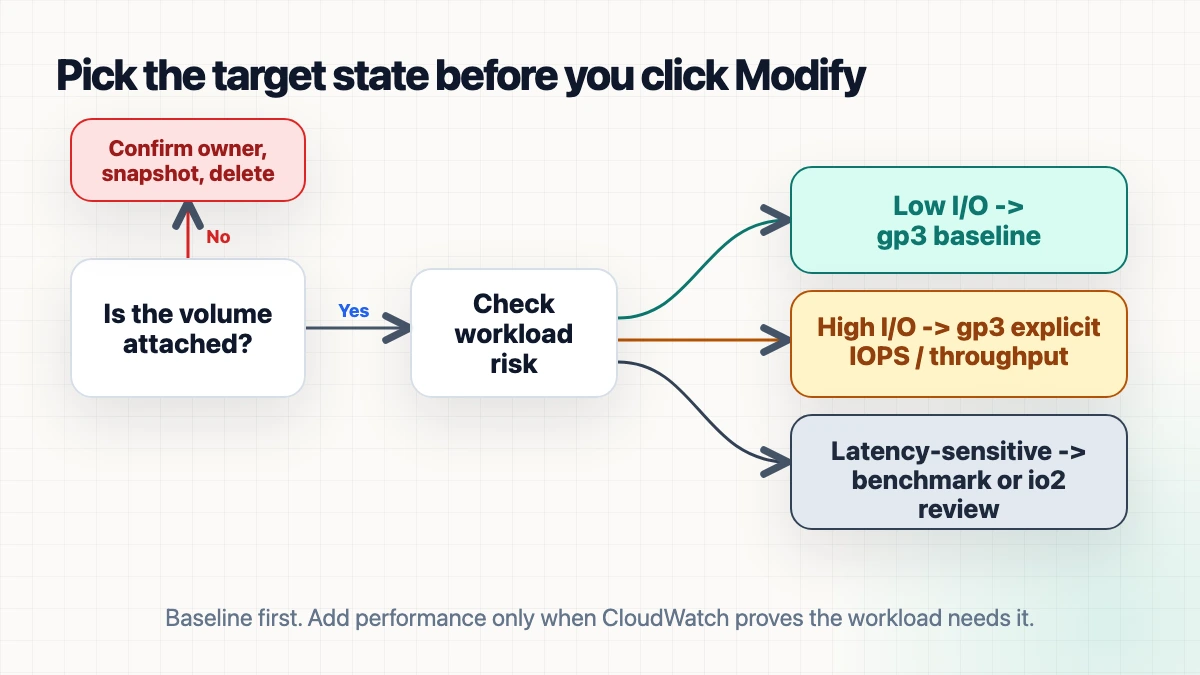
Don't do this as a blind bulk edit. Do it as a short audit.
AWS is not hiding the headline. In the EBS docs, AWS says gp3 is the latest General Purpose SSD volume type and is priced up to 20% lower per GiB than gp2. The same page says gp3 includes 3,000 IOPS and 125 MiB/s of baseline performance, and can provision more performance separately when the workload needs it.
That separation is the entire point.
gp2 couples capacity and performance. You get 3 IOPS per GiB, with a 100 IOPS floor and a 16,000 IOPS ceiling. A 100 GiB gp2 volume gets 300 baseline IOPS. A 2,000 GiB gp2 volume gets 6,000 baseline IOPS. Small gp2 volumes can burst to 3,000 IOPS using I/O credits, which is why a tiny boot volume can feel fine for months and then suddenly look guilty in CloudWatch when BurstBalance drains.
gp3 breaks that coupling. Storage is storage. IOPS and throughput are knobs. The default knob position is already better than most small gp2 volumes: 3,000 IOPS and 125 MiB/s included in the storage price.
That is why the migration is usually worth doing. It is also why the lazy version of the migration can preserve performance you never asked for and may not need.
For the US East examples in AWS's migration guidance, the monthly math is:
gp2_monthly = size_gib * 0.10
gp3_monthly =
size_gib * 0.08
+ max(iops - 3000, 0) * 0.005
+ max(throughput_mibs - 125, 0) * 0.04Check your own region before you change production storage. EBS prices are regional, and the AWS pricing page is the source of truth on publish day. The shape of the math is what matters: gp3 charges separately for performance above the included baseline.
Here is the part most migration tickets skip:
| Volume | gp2 today | gp3 baseline | gp3 matching gp2 performance |
|---|---|---|---|
| 100 GiB | $10.00/mo | $8.00/mo | $8.12/mo |
| 500 GiB | $50.00/mo | $40.00/mo | $45.00/mo |
| 2,000 GiB | $200.00/mo | $160.00/mo | $180.00/mo |
| 6,000 GiB | $600.00/mo | $480.00/mo | $550.00/mo |
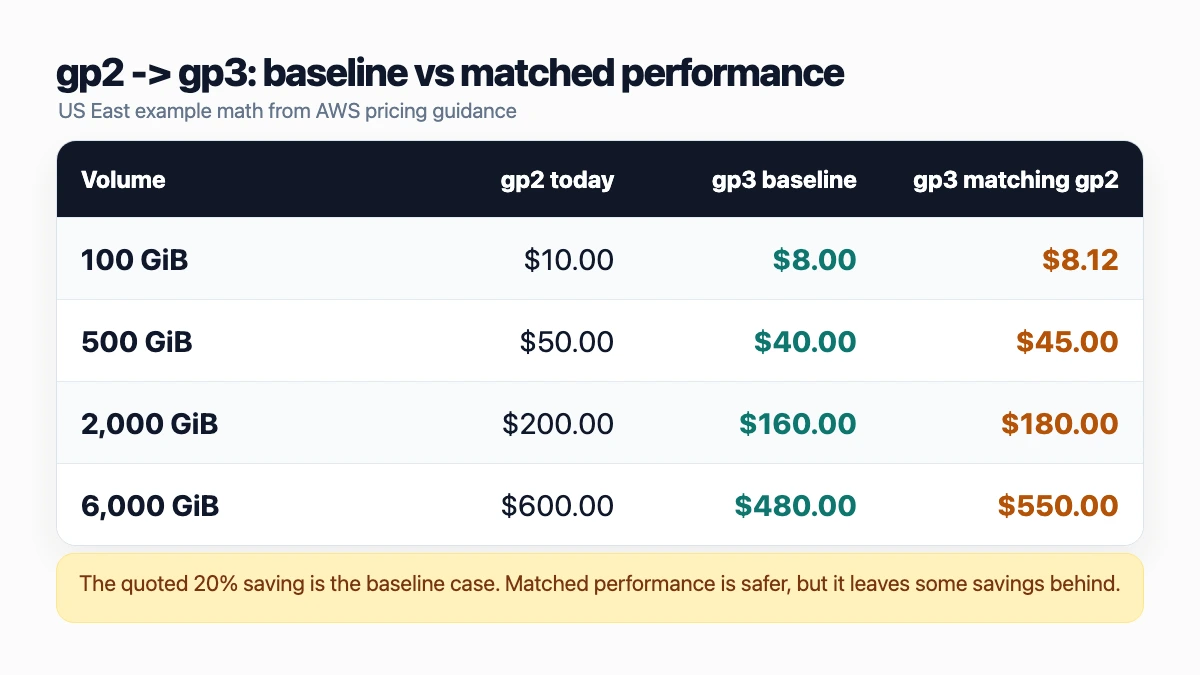
The quoted 20% saving is the baseline case. Matched performance is safer, but it can leave part of the saving on the table.
The first gp3 column is the one people quote. The second is what you may get if you preserve gp2-equivalent performance. Both are official AWS example patterns, and both are legitimate target states.
The question is not "is gp3 cheaper?" It usually is. AWS Prescriptive Guidance even says gp3 is always cheaper than gp2 when configured at the same performance level.
The better question is: "Should this volume keep the performance it had, or was that performance just a side effect of being too large?"
For a 500 GiB log volume with no latency-sensitive workload, paying the extra $5/month to preserve 250 MiB/s is probably superstition. For an old database volume that actually pushes sequential reads near that ceiling during reports, it may be cheap insurance. Same volume size. Different answer.
Elastic Volumes has a behavior I like and still do not trust as a cost policy.
If you modify a gp2 volume to gp3 and do not specify IOPS or throughput, Amazon EBS automatically provisions either equivalent performance to the source gp2 volume or the baseline gp3 performance, whichever is higher. AWS gives the example of a 500 GiB gp2 volume: it has 1,500 IOPS and 250 MiB/s of throughput. If you switch it to gp3 without setting performance, EBS gives it 3,000 IOPS and 250 MiB/s.
That is a safe default. It protects the operator who clicks through the console on a production volume and does not know which workload is attached. I am glad AWS picked safety there.
But safety is not the same as intent.
If you run a bulk migration and let that default choose for every volume, you are saying, "keep every accidental performance entitlement unless AWS lowers it for me." That is not an optimization strategy. That is a change-management strategy. Sometimes that is exactly what you need. Just be honest about which one you are doing.
Here is the rule I use:
| Volume pattern | Target |
|---|---|
| Boot volumes, dev/staging volumes, low-I/O app volumes | gp3, 3,000 IOPS, 125 MiB/s |
Production volumes with no BurstBalance pressure and low queue length | gp3, 3,000 IOPS, 125 MiB/s |
Large gp2 volumes where size exists for data, not performance | gp3 baseline first, unless metrics prove otherwise |
| Volumes with sustained high read/write ops or throughput | gp3 with explicit IOPS/throughput from observed demand |
| Latency-sensitive databases already near limits | benchmark, or consider io2 instead of pretending gp3 is magic |
Here's what I'd actually do: default to gp3 baseline, then add performance back only where the metrics force your hand.
The migration is simple after the target state is honest.
Start with inventory. Pick the region where your bill says EBS is highest and list the gp2 volumes:
aws ec2 describe-volumes \
--region us-east-1 \
--filters Name=volume-type,Values=gp2 \
--query 'Volumes[].{VolumeId:VolumeId,GiB:Size,State:State,AZ:AvailabilityZone,Instance:Attachments[0].InstanceId,Device:Attachments[0].Device,Created:CreateTime}' \
--output tableThen get the blunt savings ceiling:
aws ec2 describe-volumes \
--region us-east-1 \
--filters Name=volume-type,Values=gp2 \
--query 'sum(Volumes[].Size)' \
--output textIf that returns 8400, the rough storage-only opportunity in the US East example is:
gp2: 8,400 GiB * $0.10 = $840/mo
gp3 baseline: 8,400 GiB * $0.08 = $672/mo
ceiling: $840 - $672 = $168/mo, or $2,016/yrThat is the maximum simple win before performance add-ons. It is not the guaranteed win.
Now bucket the results:
- Under 1 TiB: likely easy.
gp3baseline gives 3,000 IOPS without relying ongp2burst credits. - 1 TiB to 5.3 TiB: watch carefully.
gp2baseline rises above 3,000 IOPS in this range. - 5.3 TiB and above:
gp2is already at the 16,000 IOPS ceiling. Do not assume baselinegp3is equivalent.
That bucket cut is not perfect. It is just fast. The real answer comes from CloudWatch.
For attached volumes, EBS publishes per-volume CloudWatch metrics in the AWS/EBS namespace. The old reliable metrics are VolumeReadOps, VolumeWriteOps, VolumeReadBytes, VolumeWriteBytes, VolumeQueueLength, and BurstBalance. On Nitro-based instances, AWS also publishes VolumeAvgIOPS and VolumeAvgThroughput, which make this easier.
I look at 14 to 30 days, not one afternoon. For each attached production volume, I want to know:
- Did
BurstBalanceever get low ongp2? - Did queue length climb during the same windows?
- What was the peak read/write IOPS?
- What was the peak throughput in MiB/s?
- Is the attached instance itself the bottleneck?
The last question matters. AWS's EBS performance docs are blunt about this: if you are not getting the IOPS or throughput you expect, make sure the EC2 instance bandwidth is not the limiting factor. Paying for 16,000 IOPS on a volume attached to an instance that cannot drive them is a clean way to turn a migration into theater.
If the volume has no burst pressure, low queue length, and peak throughput under 125 MiB/s, I do not preserve the old gp2 throughput. I set gp3 baseline and move on.
If the volume regularly needs more, I set the knobs explicitly. Not because AWS's default is bad, but because I want the pull request to say what we meant.
Before modifying a volume that contains valuable data, AWS recommends creating a snapshot. I treat that as optional for disposable dev volumes and non-optional for production state.
For a low-risk baseline migration:
aws ec2 modify-volume \
--region us-east-1 \
--volume-id vol-0123456789abcdef0 \
--volume-type gp3 \
--iops 3000 \
--throughput 125For a volume where the metrics justify more performance:
aws ec2 modify-volume \
--region us-east-1 \
--volume-id vol-0123456789abcdef0 \
--volume-type gp3 \
--iops 6000 \
--throughput 250Then watch the modification:
aws ec2 describe-volumes-modifications \
--region us-east-1 \
--volume-ids vol-0123456789abcdef0 \
--query 'VolumesModifications[].{State:ModificationState,Progress:Progress,TargetType:TargetVolumeType,TargetIops:TargetIops,TargetThroughput:TargetThroughput}'On supported instances, Elastic Volumes can change type, IOPS, and throughput without detaching the volume or restarting the instance. The change is not instant. AWS says modifications can take minutes to hours, and a fully used 1 TiB volume can take about six hours to move to a new performance configuration. Some cases take longer.
Also: do not resize the file system unless you changed the size. A type-only gp2 to gp3 migration does not require an xfs_growfs or resize2fs step. If your runbook includes one for every migration, it was probably copied from a "make disk bigger" page.
There are cases where I would not batch this.
I would not blind-change a database volume whose latency budget is already tight. General Purpose SSD is still General Purpose SSD. If the workload needs lower outlier latency, or if it is already near gp3 limits, the conversation might be io2, schema changes, caching, or separating write-ahead logs from data. A cheaper volume type is not a database performance plan.
I would not treat a huge gp2 volume as waste just because the file system has free space. gp3 does not shrink capacity. If the real problem is "this 6 TiB disk only contains 900 GiB of data," gp3 changes the price per GiB but does not fix the over-provisioned GiB. Shrinking EBS still means creating a smaller volume and migrating data at the file-system or application layer.
I would not skip ownership. A detached gp2 volume in available state is a cleanup candidate, not a migration candidate. Find the owner, snapshot if needed, delete it if it is truly orphaned. Migrating dead disks to cheaper dead disks is not victory.
And I would not run this during the same window as an instance family migration, database upgrade, storage resize, or filesystem change. The gp2 to gp3 move is intentionally boring. Keep it boring so rollback analysis is possible if something gets weird.
Start with one account and one region. Pull the gp2 list. Sort by monthly storage cost. Exclude detached volumes and handle those as cleanup. For the top ten attached volumes, read 30 days of CloudWatch metrics and assign one of three target states:
| Target state | Meaning |
|---|---|
| Delete | Detached, orphaned, or confirmed stale |
gp3 baseline | 3,000 IOPS / 125 MiB/s is enough |
gp3 explicit | Set IOPS and throughput from observed demand |
Then migrate one non-production volume, monitor it, and put the exact formula in the ticket:
Before: 500 GiB gp2 = 500 * $0.10 = $50/mo
After: 500 GiB gp3 + 3000 IOPS + 125 MiB/s = 500 * $0.08 = $40/mo
Savings: $10/mo, $120/yrFor a matched-performance case:
Before: 2,000 GiB gp2 = 2000 * $0.10 = $200/mo
After:
storage = 2000 * $0.08 = $160
IOPS = (6000 - 3000) * $0.005 = $15
throughput = (250 - 125) * $0.04 = $5
total = $180/mo
Savings: $20/mo, $240/yrThat is the whole job. Not glamorous. Very worth doing.
The trap is not that gp3 is bad. gp3 is usually the right answer. The trap is pretending the migration has only one answer. The volume type is the easy part. The performance decision is where the money is.
- Amazon EBS pricing: https://aws.amazon.com/ebs/pricing/
- Amazon EBS General Purpose SSD docs: https://docs.aws.amazon.com/ebs/latest/userguide/general-purpose.html
- AWS Prescriptive Guidance gp2 to gp3 migration: https://docs.aws.amazon.com/prescriptive-guidance/latest/optimize-costs-microsoft-workloads/ebs-migrate-gp2-gp3.html
- Modify EBS volumes with Elastic Volumes: https://docs.aws.amazon.com/ebs/latest/userguide/ebs-modify-volume.html
- Request EBS volume modifications: https://docs.aws.amazon.com/ebs/latest/userguide/requesting-ebs-volume-modifications.html
- CloudWatch metrics for EBS: https://docs.aws.amazon.com/ebs/latest/userguide/using_cloudwatch_ebs.html
- Get maximum EBS-optimized performance: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-optimization-performance.html


